La Plantilla de Datos(Data Template)
es el método por el cual se comunica la solicitud de datos al motor de datos.
Se trata de un documento XML cuyos elementos colectivamente definen cómo el
motor de datos que procesa la plantilla para generar el XML. A diferencia de otros métodos la Plantilla de Datos no necesita un programa ejecutable como un .RDF ni generar código para la salida del XML.
Esto se debe a que el archivo solo contendrá la consulta de datos y la agrupación para la etiquetas del XML. El proceso de generación de XML, sera encargado por el ejecutable XDODTEXE el cual es un programa concurrente java utilizado como plantilla de BI Publisher. El propósito principal de este ejecutable es identificar el archivo de Plantilla de Datos (.xml) y ejecutar la plantilla de datos para generar los datos de salida XML sin formato, que luego puede
usarse como motor de BI Publisher de
formato a formato como en el modelo (RTF, PDF, etc)
.
La
plantilla de datos es un documento XML se compone de cuatro secciones
básicas:
- Definir parámetros
- Definir la consulta de datos
- Definir Triggers
- Definir la
estructura de datos
Esta estructura se muestra en el siguiente gráfico
Estructura de la Plantilla de Datos
El elemento <dataTemplate> es el elemento
raíz. Cuenta con un conjunto de atributos relacionados expresadas dentro de la
etiqueta <dataTemplate>. Dentro de sus carateristicas encontramos las siguientes:
El elemento <parameter> se coloca entre
las etiquetas <parameter> de apertura y
cierre. El elemento <parameter> tiene un
conjunto de atributos relacionados. Estos se expresan dentro de la etiqueta
<parameter>. Por ejemplo, el
nombre, dataType, y atributos defaultValue se expresan como
sigue:
El elemento <sqlStatement> se coloca entre las etiquetas <DataQuery> de apertura y
cierre. El elemento <sqlStatement> tiene un
atributo relacionado, name. Se expresa en la
etiqueta <sqlStatment>. La consulta se
introduce en la sección CDATA:
Los nombres de
columnas no son únicos, debe utilizar los alias en sus sentencias SELECT para
garantizar la singularidad de sus nombres de columna. Si usted no utiliza un
alias, se utiliza el nombre de la columna por defecto. Esto es importante
cuando se especifica la salida de XML en la sección de estructura de datos.
Para especificar un elemento XML de salida de su consulta se declara un
atributo de valor para la etiqueta de elemento que corresponde a la columna de
origen.
Puede utilizar
referencias léxicas para reemplazar las cláusulas que aparecen después de
SELECT, FROM, WHERE, GROUP BY, ORDER BY, o HAVING. Utilice una referencia
léxica cuando desea que el parámetro para reemplazar múltiples valores en
tiempo de ejecución.
Crear una referencia
léxica con la siguiente sintaxis: ¶metername
Definir los
parámetros léxicas de la siguiente manera:
• Antes de crear la
consulta, definir un parámetro en el paquete por defecto PL / SQL para cada
referencia léxica en la consulta. El motor de datos utiliza estos valores para
reemplazar los parámetros léxicos.
• Crear la consulta
contiene referencias léxicas.
Si dispone de varias
consultas, debe vincular a crear la salida de datos correspondiente. En la
plantilla de datos, existen dos métodos para vincular las consultas: el uso de
variables de enlace o mediante el elemento <link> para definir el vínculo
entre las consultas.
Consejo:
Para maximizar el
rendimiento al generar consultas de datos en el modelo de datos:
Pruebas de BI
Publisher han demostrado que el uso de variables de enlace es más eficiente que
el uso de la etiqueta de enlace.
El siguiente ejemplo
muestra un vínculo de consulta utilizando una variable de vinculación:
El elemento
<link> tiene un conjunto de atributos. Utilice estos atributos para
especificar la información de los vínculos necesarios. Se puede especificar
cualquier número de enlaces. Por ejemplo:
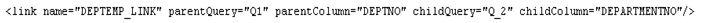

<DataTriggers> ejecutan funciones
PL/SQL en momentos específicos durante la ejecución y generación de salida XML.
El uso de las capacidades de procesamiento condicional de PL/SQL para estos triggers, puede hacer cosas
como realizar tareas de inicialización y acceder a la base de datos.
DataTriggers son opcionales, y
usted puede tener tantos elementos <dataTrigger> según sea necesario. El elemento <dataTrigger> tiene un
conjunto de atributos relacionados. Estos se expresan dentro de la etiqueta
<DataTrigger>. Por ejemplo,
los atributos de nombre y origen se expresan como sigue:
En la sección de
estructura de datos <DataStructure> se define cuál será la salida XML y cómo se estructurará.
La jerarquía del grupo completa está disponible para la salida. Puede
especificar todas las columnas dentro de cada grupo y romper el orden de las
columnas, se puede utilizar resúmenes y marcadores para personalizar aún más
dentro de los grupos. Se requiere que la sección de estructura de datos para
múltiples consultas y opcional para las consultas individuales. Si se omite
para una única consulta, el motor de datos generará salida XML.
En la plantilla de
datos, el elemento <Group> se coloca entre las etiquetas de apertura y
cierre <DataStructure>. Cada
<grupo> tiene un conjunto de elementos relacionados. Se puede definir una
jerarquía del grupo y el nombre de las etiquetas del elemento de la salida XML.
La siguiente tabla se
muestran los atributos de la etiqueta elemento <Group>:
En la siguiente tabla se muestran los atributos de la
etiqueta elemento <Element>:
Pasos para cargar la Plantilla de Datos
Debe realizar lo
siguiente:
a)Crear Programa
concurrente bajo el ejecutable XDODTEXE
b)Crear la definición
de datos
c)Cargar la Plantilla
de Datos
d)Crear la plantilla RTF
e)Generación de Output



















